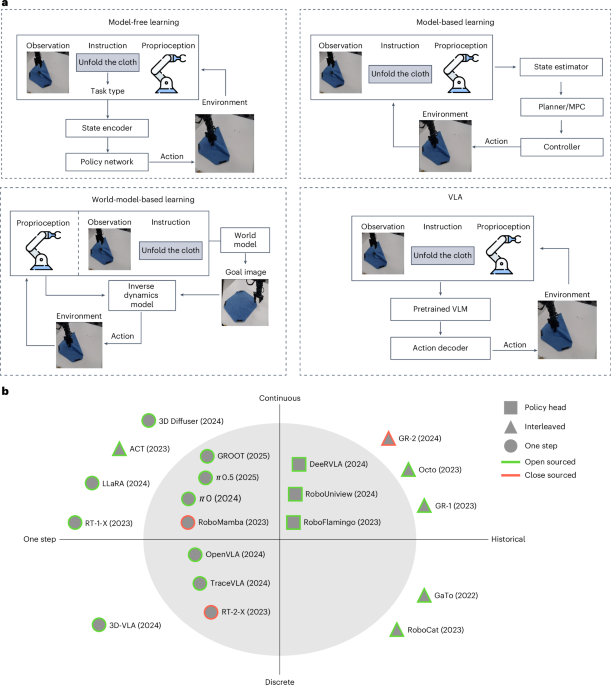
• Abstract To utilize foundation vision-language models (VLMs) for robotic tasks and motion planning, the community has proposed different methods for injecting action components into VLMs and building the vision-language-action models (VLAs). • Here we disclose the key factors that significantly influence the performance of VLA on robot manipulation problems and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures and when to add cross-embodiment data. • The obtained results convince us firmly to explain why we prefer VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. • Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. • In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. • We open-source all details, including codes, models, datasets and toolkits, along with detailed training and evaluation recipes at robovlms.github.io.
Article Summaries:
- Researchers have introduced RoboVLMs, a new family of vision‑language‑action (VLA) models designed to streamline the integration of foundation vision‑language models (VLMs) into robotic manipulation. By systematically evaluating over 8 VLM backbones, 4 policy architectures, and more than 600 experiments, the study identifies key design choices-backbone selection, architectural formulation, and timing of cross‑embodiment data injection-that drive performance. RoboVLMs achieve state‑of‑the‑art results on three simulation tasks and real‑world experiments while requiring minimal manual tuning. The authors provide a detailed guidebook and open‑source framework (GitHub, Zenodo) to support future VLA research.
Sources: