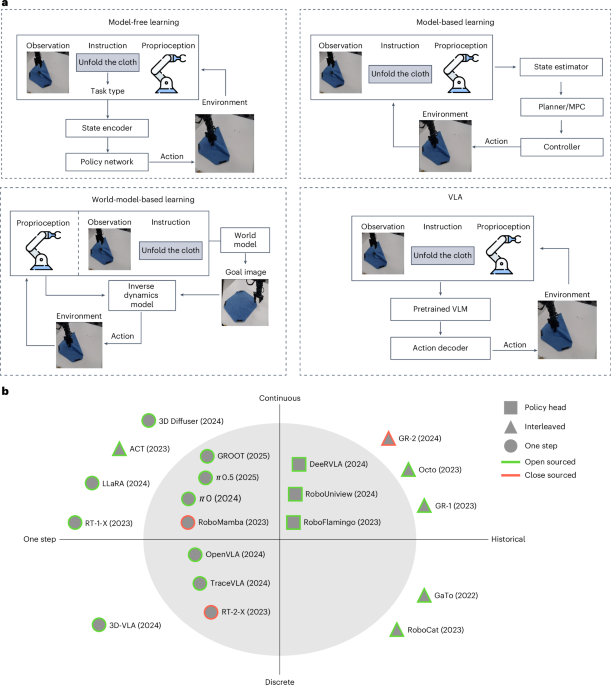
What matters in building vision-language-action models for generalist robots
• Abstract To utilize foundation vision-language models (VLMs) for robotic tasks and motion planning, the community has proposed different methods for injecting action components i





