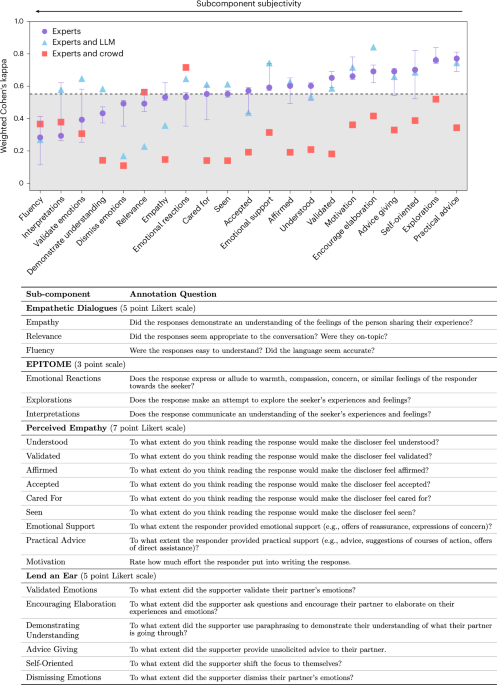
• Abstract Large language models (LLMs) excel at generating empathic responses in text-based conversations. • But, how reliably do they judge the nuances of empathic communication? • Here we investigate this question by comparing how experts, crowdworkers and LLMs annotate empathic communication across four evaluative frameworks drawn from psychology, natural language processing and communications applied to 200 real-world conversations where one speaker shares a personal problem and the other offers support. • Drawing on 3,150 expert annotations, 2,844 crowd annotations and 3,150 LLM annotations, we assess interrater reliability between these three annotator groups. • We find that expert agreement is high but varies across the frameworks’ subcomponents depending on their clarity, complexity and subjectivity. • We show that expert agreement offers a more informative benchmark for contextualizing LLM performance than standard classification metrics.
Article Summaries:
- A recent study tested whether large language models (LLMs) can reliably assess empathic communication. Researchers compared annotations from experts, crowdworkers, and LLMs on 200 real‑world conversations where one person shared a personal problem and the other offered support. Using 3,150 expert, 2,844 crowd, and 3,150 LLM annotations across four psychological and NLP frameworks, they measured inter‑rater reliability. Expert agreement was high but varied by subcomponent. LLMs consistently approached expert‑level reliability and outperformed crowdworkers. The authors argue that, when benchmarked appropriately, LLMs can provide transparent, reliable evaluation for emotionally sensitive applications such as therapeutic chatbots.
Sources: