Implicit Intelligence -- Evaluating Agents on What Users Don't Say
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Implicit Intelligence – Evaluating Agents on What Users Don’t Say View PDF HTML (experimental)Abstrac
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Implicit Intelligence – Evaluating Agents on What Users Don’t Say View PDF HTML (experimental)Abstrac
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:Inner Speech as Behavior Guides: Steerable Imitation of Diverse Behaviors for Human-AI coordination Vi
• Computer Science > Computers and Society [Submitted on 18 Feb 2026] Title:Is Robot Labor Labor? • Delivery Robots and the Politics of Work in Public Space View PDF HTML (experime
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:KairosVL: Orchestrating Time Series and Semantics for Unified Reasoning View PDF HTML (experimental)Ab
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Learning to Rewrite Tool Descriptions for Reliable LLM-Agent Tool Use View PDF HTML (experimental)Abst
• Computer Science > Machine Learning [Submitted on 21 Feb 2026] Title:MoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs View PDF HTML (experimental)Abstract:
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Multilevel Determinants of Overweight and Obesity Among U.S. • Children Aged 10-17: Comparative Evalua
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:Online Algorithms with Unreliable Guidance View PDF HTML (experimental)Abstract:This paper introduces
• Computer Science > Cryptography and Security [Submitted on 22 Feb 2026] Title:OpenPort Protocol: A Security Governance Specification for AI Agent Tool Access View PDF HTML (exper
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:Physics-based phenomenological characterization of cross-modal bias in multimodal models View PDF HTML
• Computer Science > Computers and Society [Submitted on 9 Feb 2026] Title:Playsemble: Learning Low-Level Programming Through Interactive Games View PDF HTML (experimental)Abstract
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:PreScience: A Benchmark for Forecasting Scientific Contributions View PDFAbstract:Can AI systems train
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:PromptCD: Test-Time Behavior Enhancement via Polarity-Prompt Contrastive Decoding View PDFAbstract:Rel
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:Recursive Belief Vision Language Model View PDF HTML (experimental)Abstract:Current vision-language-ac
• Computer Science > Machine Learning [Submitted on 12 Feb 2026] Title:Tensor Network Generator-Enhanced Optimization for Traveling Salesman Problem View PDF HTML (experimental)Abs
• Computer Science > Computer Vision and Pattern Recognition [Submitted on 4 Feb 2026] Title:VISION-ICE: Video-based Interpretation and Spatial Identification of Arrhythmia Origins
• Computer Science > Cryptography and Security [Submitted on 21 Feb 2026] Title:When Backdoors Go Beyond Triggers: Semantic Drift in Diffusion Models Under Encoder Attacks View PDF
• Computer Science > Artificial Intelligence [Submitted on 24 Feb 2026] Title:When can we trust untrusted monitoring? • A safety case sketch across collusion strategies View PDF HT

• Carnegie Mellon University School of Computer Science The Breakdown PeerCoPilot is a chatbot built to support peer-led mental health services. • The tool uses vetted service data

• Adam KohlhaasTuesday, February 24, 2026Print this page. • Dana Scott, the Hillman University Professor of Computer Science, Philosophy and Mathematical Logic (Emeritus), has rece
• Perlin noise used as AI coordinator for large-scale NPC control. • Combines behavior parameterization, action timing, spawn/event generation layers. • Outperforms random, filtere
• ABD benchmark tests default‑exception abduction in finite first‑order logical worlds. • Models generate sparse exception formulas to restore satisfiability under abnormality pred
• Asymptotic Semantic Collapse: dominant context absorbs individual semantics in multi‑agent language systems. • Dominant Anchor Node with infinite inertia drives asymptotic alignm
• Chart summarization remains key for data accessibility but current methods lack deep insight extraction. • Existing MLLMs focus on low-level descriptions, missing the core analyt
• Current AI safety benchmarks assess agents in isolation, ignoring human‑AI interaction dynamics. • Single‑channel evaluation misrepresents operational safety, unlike redundancy‑b
• ConfSpec introduces confidence‑gated cascaded verification for step‑level speculative reasoning efficiently. • Small draft models quickly verify reasoning steps, accepting high‑c
• GEARS reframes ranking optimization as autonomous discovery in programmable experimentation. • Uses Specialized Agent Skills to embed ranking expert knowledge into reusable reaso
• Multi-Agent System (MAS) integrates Evidence-Centered Design (ECD) to automate NGSS-aligned science assessment creation. • MAS ensembles multiple large language models, each with
• DREAM introduces agentic evaluation for AI research agents, addressing lack of ground truth. • Highlights Mirage of Synthesis: surface fluency can mask factual and reasoning flaw
• LLMs increasingly used as scientific copilots, but research-level math evidence limited. • Case study uses ChatGPT-5.2 (Thinking) to resolve Conjecture 20 on spectral region of 4
• AI-driven UI design now adapts and personalizes, but also amplifies dark pattern risks. • Dark patterns exploit psychological biases, learned from existing deceptive data, becomi
• Introduces Red‑Blue Reinforcement (R‑BR) problem: minimize client reallocations under budget constraints. • Goal: reduce number of servers needed by a specified amount while keep
• AI‑driven mental‑health apps raise ethical concerns about privacy, bias, and user trust. • Researchers built an NLP framework to analyze user reviews from Google Play and Apple A
• Addresses bidirectional model learnability gap in federated LLM-SLM reasoning collaboration. • Introduces LaDa framework with learnability-aware data filter for high-reward sampl
• Leveraged generative LLMs to auto‑generate Adaptation Manager code for CAS systems. • Introduced vibe coding feedback loops to iteratively test and refine generated AMs. • Develo
• FineRef introduces fine-grained error reflection for citation mismatch and irrelevance in long‑form LLM generation. • Two‑stage training: supervised fine‑tuning with attempt‑refl
• Evaluated 11 LLMs generating six-word subject lines for German counselling emails. • Used hierarchical assessment: first categorize outputs, then rank within categories. • Nine a
• LLMs leverage shared cultural patterns to interpret and act in social contexts. • Identity is central to judgment, yet current governance focuses solely on bias mitigation. • Bia
• GenPlanner uses diffusion and flow matching to generate path plans from noise. • Multi-channel conditioning incorporates obstacle maps, start and goal positions. • Iterative deno
• HRDL extends reward design to encode nuanced human preferences for long-horizon tasks. • L2HR translates natural language specifications into hierarchical reward signals for RL a
• Introduces High-Dimensional PCG (HDPCG) treating gameplay mechanics as first-class coordinates. • Adds discrete layer dimension (x,y,z,l) for 2.5D/3.5D mechanics like gravity inv
• INDUCTION benchmark tests finite-structure concept synthesis in first‑order logic across small relational worlds. • Models output a single logical formula that uniformly explains
• INSURE‑Dial is the first public benchmark for compliance‑aware voice agents in insurance calls. • Corpus contains 50 real AI‑initiated calls and 1,000 synthetic calls, averaging
• LAMMI-Pathology introduces a tool-centric, bottom‑up LVLM‑agent framework for pathology image analysis.\n• Customized domain‑adaptive tools cluster by style, forming component ag
• Replication crisis threatens empirical research credibility, driven by high costs and low incentives for replication. • LLMs accelerate scientific output by automating writing, c
• LunaAI chatbot prioritizes politeness and fairness in healthcare conversations. • Developed via user-centered design and literature review for diverse interactions. • Built on Go
• AI analysts replicate many‑analyst diversity at scale using large language models. • LLMs and prompt framing generate distinct analytic pipelines on the same dataset. • An AI aud
• Modularity underpins human intelligence, enabling efficient learning and strong generalization across diverse tasks. • AI systems rely on massive data and compute, yet lack modul
• Visual intelligence often treats semantics as static latent property, assuming meaning via geometric proximity. • Authors argue semantics must be dynamic, tied to physical agent
• Diffusion-based framework refines system prompts via masked denoising in an iterative manner. • Conditions on interaction traces: user queries, model responses, and optional feed
• RA-QA dataset: 7.5M QA pairs, 60+ attributes, 3 question types. • Curated 11 respiratory audio datasets, first multimodal QA resource bridging audio and natural language. • Bench
• FedTPG introduces dynamic text-driven prompt generation for vision-language models in federated settings. • Replication evaluated on six datasets, achieving 74.58% seen, 76.00% u
• LLMs increasingly synthesize research into structured reports, but logical reliability remains unassessed. • ReportLogic benchmark quantifies report‑level logical quality for dee
• Reinterprets LLM softmax as Energy-Based Model, enabling energy tracking during decoding. • Introduces training‑free metrics: spilled energy and marginalized energy from logits.
• Deepfake and synthetic media are increasingly used as avatar tutors in multilingual MOOCs. • They boost social presence and participation by providing culturally relevant, multil
• TEB introduces task-aware exploration for visual RL with sparse rewards. • Uses predictive bisimulation metric to learn behaviorally grounded task representations. • Adds predict
• Schema-Guided Dialogue (SGD) and Model Context Protocol (MCP) converge as unified deterministic LLM-agent frameworks. • Both rely on schemas to encode tool signatures, operationa
• Reproducibility crisis shows paper‑centric reviews limit research rigor. • AI agents producing research outputs amplify evaluation challenges. • Introduces execution‑grounded eva
• TPRU dataset addresses temporal and procedural gaps in multimodal LLMs, enabling richer embodied AI. • Comprised of robotic manipulation and GUI navigation scenes with 3 tasks: T
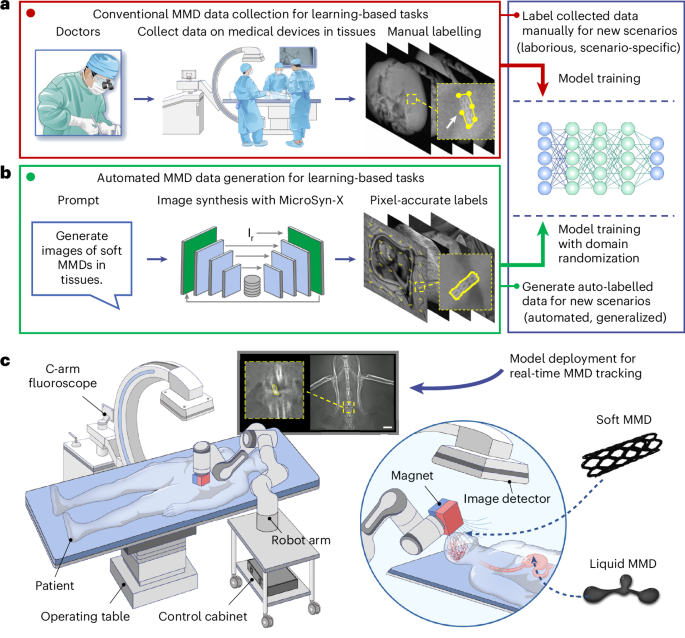
• Abstract The clinical translation of miniature medical devices (MMDs) for minimally invasive surgery promises transformative advances in biomedical engineering, offering enhanced