Beyond single-channel agentic benchmarking
• Current AI safety benchmarks assess agents in isolation, ignoring human‑AI interaction dynamics. • Single‑channel evaluation misrepresents operational safety, unlike redundancy‑b
• Current AI safety benchmarks assess agents in isolation, ignoring human‑AI interaction dynamics. • Single‑channel evaluation misrepresents operational safety, unlike redundancy‑b
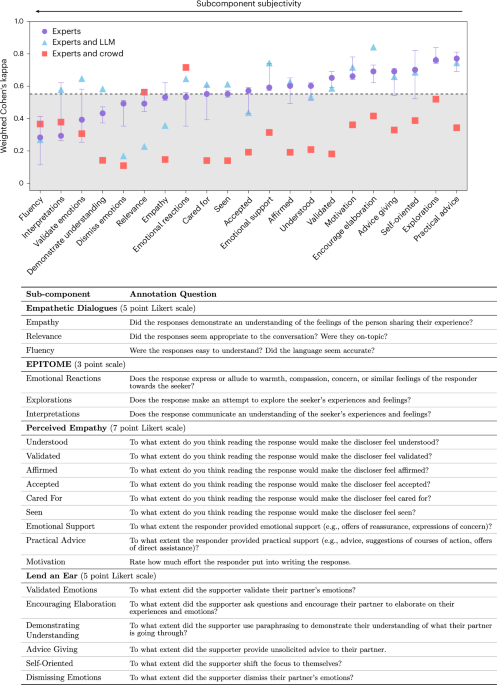
• LLMs generate empathic responses, but reliability of judging empathy remains unclear. • Study compares expert, crowdworker, and LLM annotations across four psychological framewor

• FeaturedIntroducing ‘AI Unlocked: Decoding Prompt Injection,’ a New Interactive ChallengeFeb 18, 2026Exposing Insider Threats through Data Protection, Identity, and HR ContextFeb