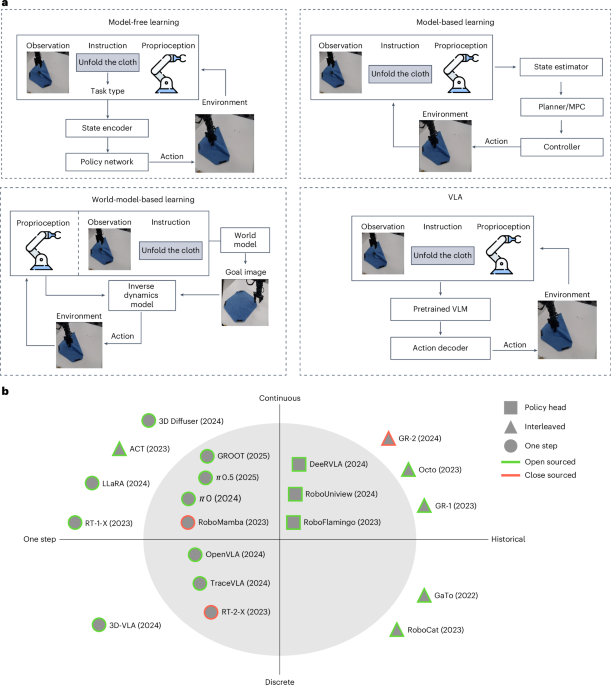
What matters in building vision-language-action models for generalist robots
• Explores how to embed action modules into vision‑language models for robotic manipulation. • Evaluates 8 VLM backbones and 4 policy architectures across 600 experiments. • Identi