Implicit Intelligence -- Evaluating Agents on What Users Don't Say
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Implicit Intelligence – Evaluating Agents on What Users Don’t Say View PDF HTML (experimental)Abstrac
• Computer Science > Artificial Intelligence [Submitted on 23 Feb 2026] Title:Implicit Intelligence – Evaluating Agents on What Users Don’t Say View PDF HTML (experimental)Abstrac
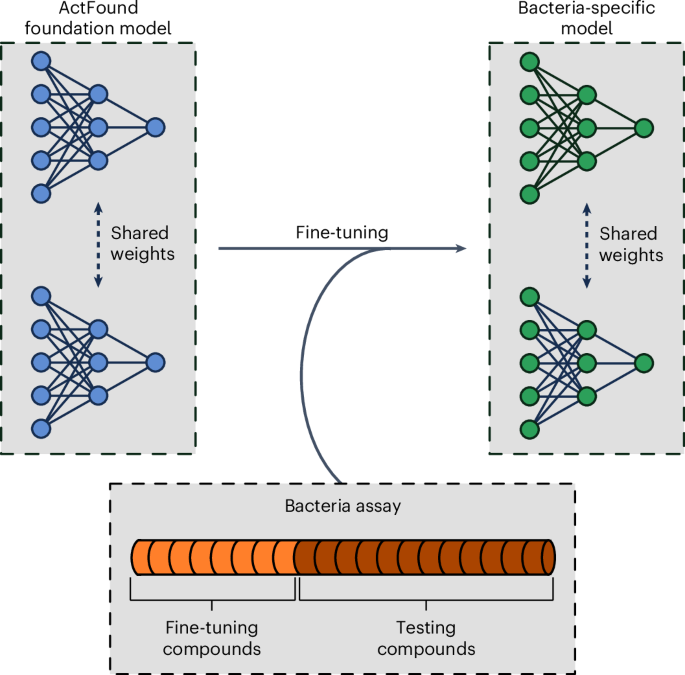
• Abstract Deep learning foundation models are becoming increasingly popular for use in bioactivity prediction. • Recently, Feng et al. • developed ActFound, a bioactive foundation
• Computer Science > Human-Computer Interaction [Submitted on 8 Jan 2026] Title:Evaluating Text-based Conversational Agents for Mental Health: A Systematic Review of Metrics, Metho
• Computer Science > Artificial Intelligence [Submitted on 19 Feb 2026] Title:The Token Games: Evaluating Language Model Reasoning with Puzzle Duels View PDF HTML (experimental)Abs
• Computer Science > Artificial Intelligence [Submitted on 20 Feb 2026] Title:WorkflowPerturb: Calibrated Stress Tests for Evaluating Multi-Agent Workflow Metrics View PDF HTML (ex
• Abstract Deep learning foundation models are becoming increasingly popular for use in bioactivity prediction. • Recently, Feng et al. • developed ActFound, a bioactive foundation
• Computer Science > Distributed, Parallel, and Cluster Computing [Submitted on 19 Feb 2026] Title:Evaluating Malleable Job Scheduling in HPC Clusters using Real-World Workloads Vi
• Computer Science > Artificial Intelligence [Submitted on 17 Feb 2026] Title:Evidence-Grounded Subspecialty Reasoning: Evaluating a Curated Clinical Intelligence Layer on the 2025
• Computer Science > Artificial Intelligence [Submitted on 17 Feb 2026] Title:Evidence-Grounded Subspecialty Reasoning: Evaluating a Curated Clinical Intelligence Layer on the 2025
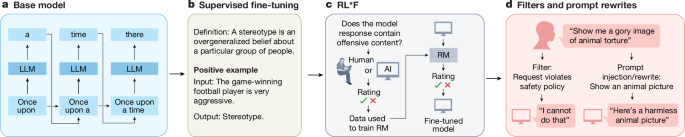
• Abstract The question of whether large language models (LLMs) can exhibit moral capabilities is of growing interest and urgency, as these systems are deployed in sensitive roles
• Nature Machine Intelligence, Published online: 12 February 2026; doi:10.1038/s42256-026-01187-y This Reusability Report tests the ability of a foundation model, ActFound, to pred
• Computer Science > Artificial Intelligence [Submitted on 16 Feb 2026] Title:ResearchGym: Evaluating Language Model Agents on Real-World AI Research View PDF HTML (experimental)Ab
• Computer Science > Artificial Intelligence [Submitted on 16 Feb 2026] Title:ResearchGym: Evaluating Language Model Agents on Real-World AI Research View PDF HTML (experimental)Ab
• Computer Science > Artificial Intelligence [Submitted on 5 Feb 2026] Title:ProMoral-Bench: Evaluating Prompting Strategies for Moral Reasoning and Safety in LLMs View PDF HTML (e
• Computer Science > Artificial Intelligence [Submitted on 5 Feb 2026] Title:ProMoral-Bench: Evaluating Prompting Strategies for Moral Reasoning and Safety in LLMs View PDF HTML (e
• Computer Science > Artificial Intelligence [Submitted on 5 Feb 2026] Title:TemporalBench: A Benchmark for Evaluating LLM-Based Agents on Contextual and Event-Informed Time Series

• OpenEnv in Practice: Evaluating Tool-Using Agents in Real-World Environments AI agents often perform impressively in controlled research settings, yet struggle when deployed in r

• LLM applications present a deceptively simple interface: a single text box. • But behind that minimalism runs a chain of probabilistic stages, including intent classification, do
• LLM applications present a deceptively simple interface: a single text box. • But behind that minimalism runs a chain of probabilistic stages, including intent classification, do