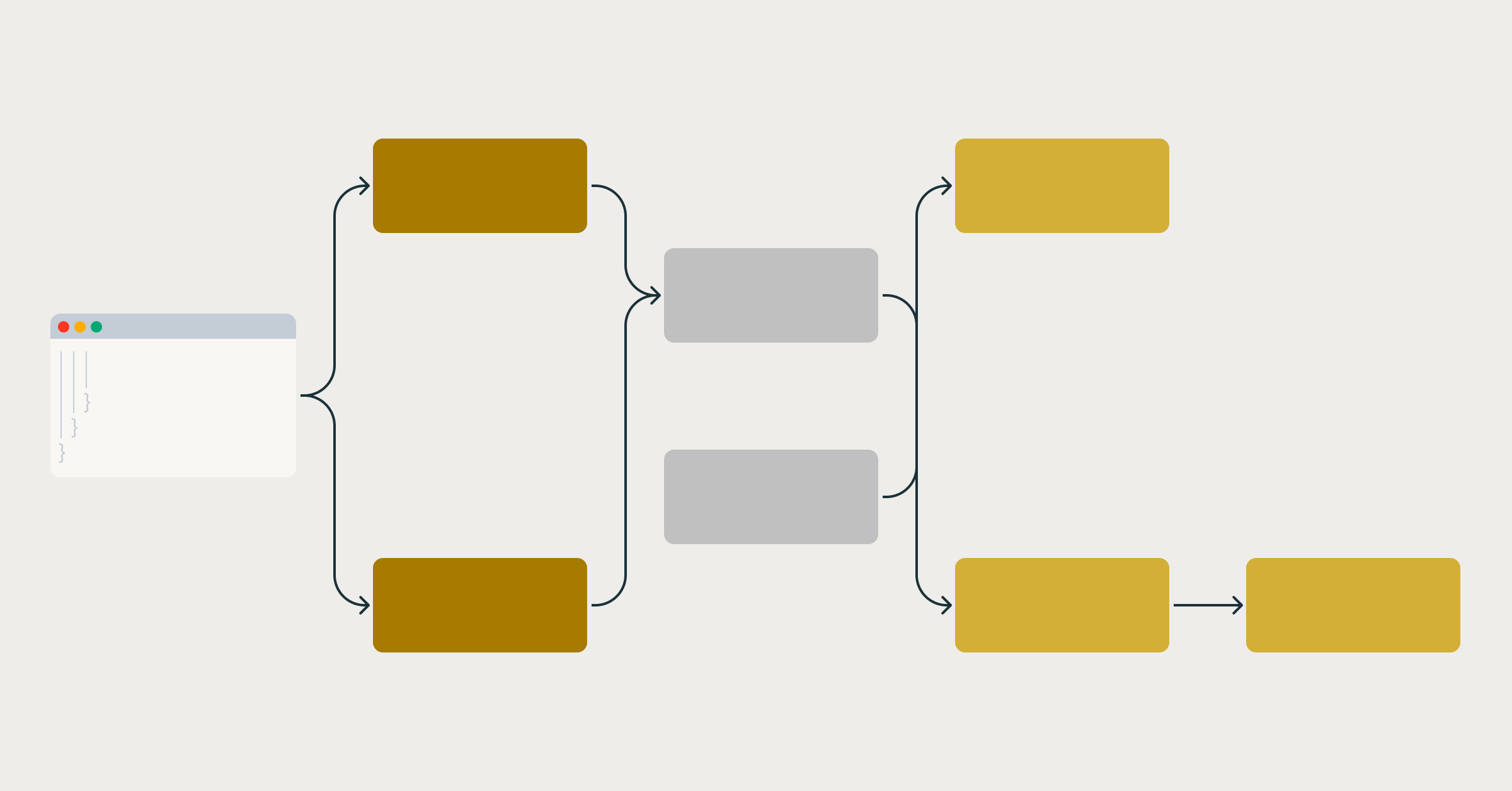
• Share this post Keep up with us Summary Why hand-built pipelines break down as data volume and complexity growHow Spark Declarative Pipelines replace glue code with pipeline-aware executionWhat changes when Spark handles dependencies, incrementality, and recovery Why hand-built pipelines break down as data volume and complexity grow How Spark Declarative Pipelines replace glue code with pipeline-aware execution What changes when Spark handles dependencies, incrementality, and recovery Data engineering teams are under pressure to deliver higher quality data faster, but the work of building and operating pipelines is getting harder, not easier. • We interviewed hundreds of data engineers and studied millions of real-world workloads and found something surprising: data engineers spend the majority of their time not on writing code but on theoperational burden generated by stitching together tools. • The reason is simple: existing data engineering frameworks force data engineers to manually handle orchestration, incremental data processing, data quality and backfills - all common tasks for production pipelines. • As data volumes and use cases grow, this operational burden compounds, turning data engineering into a bottleneck for the business rather than an accelerator. • This isn’t the first time the industry has hit this wall. • Early data processing required writing a new program for every question, which didn’t scale.
Article Summaries:
- Spark Declarative Pipelines (SDP) aim to reduce the operational burden that has become a bottleneck for data engineering teams. Surveys of hundreds of engineers and analysis of millions of workloads show that most time is spent stitching together tools for orchestration, incremental processing, data quality, and backfills rather than writing code. SDP extends the declarative model of SQL to entire pipelines, letting Spark automatically infer dataset dependencies, build a single execution plan, and update only changed data. It embeds data‑quality rules, handles backfills and late arrivals, and manages retries and failure recovery without external orchestrators, promising faster, higher‑quality data delivery.
- Data engineering teams are increasingly burdened by the operational overhead of stitching together tools for orchestration, incremental processing, data quality, and backfills. A study of millions of workloads found that most engineer time is spent on these tasks rather than coding. Spark Declarative Pipelines (SDP) aim to solve this by extending declarative concepts from individual SQL queries to entire pipelines. SDP lets users declare desired datasets and lets Spark automatically infer dependencies, build a single execution plan, and manage incremental updates, quality checks, and failure recovery. The result is a more efficient, reliable pipeline workflow that reduces manual orchestration and speeds data delivery.
Sources:
- https://www.databricks.com/blog/spark-declarative-pipelines-why-data-engineering-needs-become-end-end-declarative (Latest source article published: 2026-02-23 21:40 UTC)