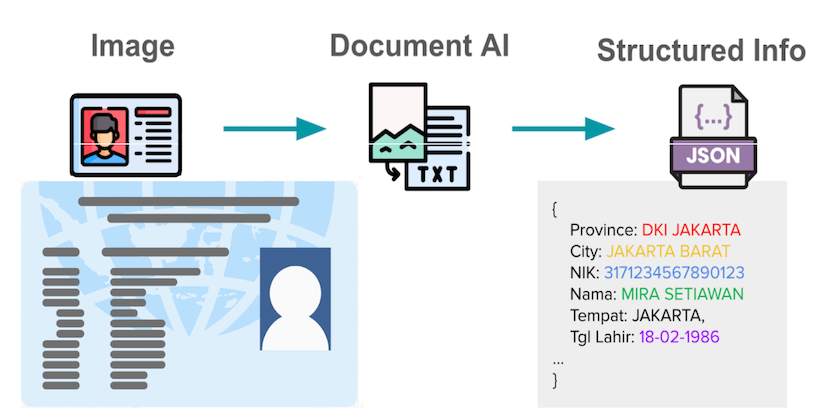
• How we built a custom vision LLM to improve document processing at Grab Introduction In the world of digital services, accurate extraction of information from user-submitted documents such as identification (ID) cards, driver’s licenses, and registration certificates is a critical first step for processes like electronic know-your-customer (eKYC). • This task is especially challenging in Southeast Asia (SEA) due to the diversity of languages and document formats. • We began this journey to address the limitations of traditional Optical Character Recognition (OCR) systems, which struggled with the variety of document templates it had to process. • While powerful proprietary Large Language Models (LLMs) were an option, they often fell short in understanding SEA languages, produced errors, hallucinations, and had high latency. • On the other hand, open-sourced Vision LLMs were more efficient but not accurate enough for production. • This prompted us to fine-tune and ultimately develop a lightweight, specialized Vision LLM from the ground up.
Article Summaries:
- Grab developed a lightweight, custom Vision Large Language Model (LLM) to enhance document processing for e‑KYC in Southeast Asia. Traditional OCR struggled with the region’s diverse languages and formats, while commercial LLMs produced errors and high latency. The team chose Qwen2‑VL 2B as a base model because of its small size, native SEA language support, and dynamic image resolution handling. They fine‑tuned it on a synthetic dataset generated from Common Crawl text, rendered in varied fonts and backgrounds, to improve OCR and key‑information extraction accuracy. The result is a more efficient, accurate solution tailored to Grab’s document‑processing needs.
Sources: