• AWS Architecture Blog A scalable, elastic database and search solution for 1B+ vectors built on LanceDB and Amazon S3 This post was co-authored with Owen Janson, Audra Devoto, and Christopher Brown of Metagenomi. • From CRISPR gene editing to industrial biocatalysis, enzymes power some of the most transformative technologies in healthcare, energy, and manufacturing. • But discovering novel enzymes that can transform an industry - such as Cas9 for genome engineering - requires sifting through the billions of diverse enzymes encoded by organisms spanning the tree of life. • Advances in DNA sequencing and metagenomics have enabled the growth of vast public and proprietary databases containing known protein sequences, but scanning through these collections to identify high value candidates is fundamentally a big data problem as well as a biological one. • At Metagenomi, we’re developing potentially curative therapeutics by using our extensive metagenomics database (MGXdb) to build a toolbox of novel gene editing systems. • In this post, we highlight how Metagenomi is tackling the challenge of enzyme discovery at the billion protein scale by using the scalable infrastructure of Amazon Web Services (AWS) to build a high-performance protein database and search solution based on embeddings.
Article Summaries:
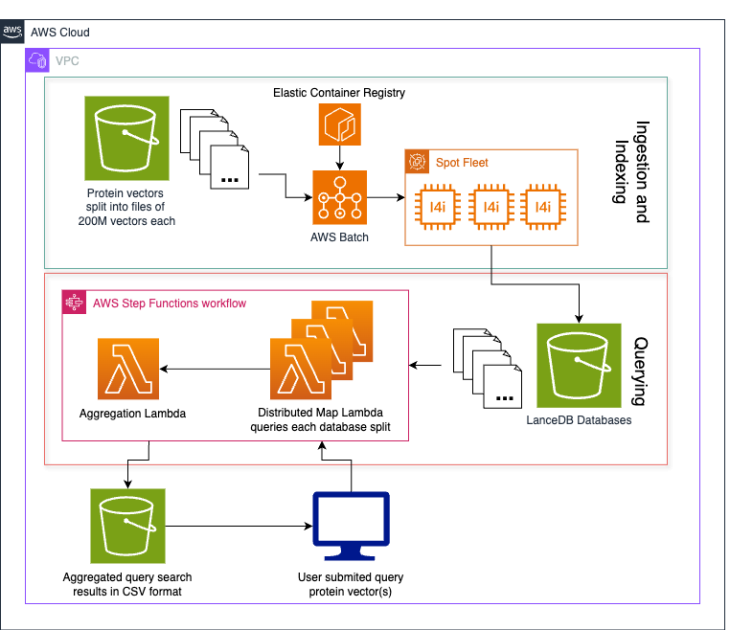
- Metagenomi announced a new, serverless architecture that lets it index and search over one billion protein vectors. The company embeds each protein sequence with a transformer‑based language model, stores the resulting vectors in Amazon S3, and uses LanceDB-an open‑source, file‑based vector database-to perform approximate nearest‑neighbor queries. By partitioning the data into S3 folders and indexing each part in parallel with AWS Lambda, the system eliminates the need for persistent disk storage or long‑running servers. The result is a low‑cost, elastic solution that turns large‑scale enzyme discovery into an on‑demand nearest‑neighbor search problem.
Sources: